






 BTC/USD-2.22%
BTC/USD-2.22% ETH/USD-3.26%
ETH/USD-3.26% LTC/USD-2.4%
LTC/USD-2.4% DOT/USD-3.53%
DOT/USD-3.53% ADA/USD-3.2%
ADA/USD-3.2% SOL/USD-3.14%
SOL/USD-3.14% XRP/USD-2.16%
XRP/USD-2.16% DOGE/US-4.56%
DOGE/US-4.56%En esta publicación, profundizamos en los detalles del problema de disponibilidad de datos y cómo afecta la escala de Ethereum.
¿Cuáles son los problemas de disponibilidad de datos?
El problema de disponibilidad de datos (DA): ¿Cómo aseguran los nodos en una red de cadena de bloques que todos los datos para un bloque recién propuesto estén realmente disponibles? Si los datos no están disponibles, el bloque puede contener transacciones maliciosas que fueron ocultadas por los productores del bloque.
Como ejemplo, supongamos que Alice es la operadora de un ZK-Rollup (ZKR). Presentó una prueba probada de ZK en Ethereum. Si no envía todos los datos de transacciones en Ethereum, es posible que el usuario del resumen aún no tenga idea del saldo de su cuenta actual a pesar de su prueba de que todas las transiciones de estado realizadas en el resumen son válidas. Debido a la naturaleza de conocimiento cero de las pruebas enviadas, las pruebas enviadas no dicen nada sobre el estado actual.
Hay un ejemplo similar en la configuración Optimistic Rollup (OPR), donde Alice envía una afirmación sobre Ethereum, pero ningún participante en la OPR puede impugnarla porque los datos de la transacción no están disponibles, por lo que no pueden volver a calcular ni impugnar la afirmación.
Para hacer frente a lo anterior, tanto OPR como ZKR están diseñados para exigir a los operadores que envíen todos los detalles de la transacción en Ethereum como "datos de llamada". Si bien esto les permite evitar el problema de DA a corto plazo, a medida que crece la cantidad de transacciones dentro de un paquete acumulativo, también aumenta la cantidad de datos que deben comprometerse, lo que limita la cantidad de escalamiento que estos paquetes acumulativos pueden proporcionar.
¿Cómo afecta esto a blockchain hoy?
Para responder a esta pregunta, primero revisemos la estructura general de bloques de una cadena de bloques similar a Ethereum y los tipos de clientes que existen en cualquier red de cadenas de bloques.
Un bloque se puede dividir en dos partes principales:
Encabezado de bloque: un pequeño encabezado de bloque contiene resúmenes y metadatos relacionados con las transacciones contenidas en el bloque.
Cuerpo del bloque: contiene todos los datos de transacciones y cuentas para la mayor parte del tamaño del bloque.
En los protocolos de cadena de bloques tradicionales, todos los nodos se consideran nodos completos que sincronizan bloques completos y validan todas las transiciones de estado. Todos los nodos gastan muchos recursos comprobando la validez de las transacciones y almacenando bloques. En el lado positivo, estos nodos no aceptarán transacciones no válidas.
Puede haber otra clase de nodos que no tengan (o no quieran gastar) los recursos para verificar cada transacción. En cambio, están interesados principalmente en conocer el estado actual de la cadena de bloques y si ciertas transacciones relacionadas con ellas están incluidas en la cadena. Estos clientes ligeros se basan en nodos completos para verificar que todas las transacciones sean válidas. Por lo tanto, en términos de seguridad, se basan en nodos completos de confianza.
Pero, ¿qué pasa si el productor del bloque no revela los datos completos detrás del bloque? Esto evita que los nodos completos validen todas las transacciones. Esto, a su vez, evita que un nodo ligero esté absolutamente seguro de que ve encabezados de bloque respaldados por todas las transacciones legítimas.
Para resolver este problema, necesitamos un mecanismo de cliente ligero para verificar la disponibilidad de los datos. Esto asegurará que los productores de bloques no puedan convencer a los clientes ligeros de ocultar datos. También obligará a los productores de bloques a divulgar partes de sus datos, lo que permitirá que toda la red acceda a bloques completos de manera coordinada.
Exploremos esta pregunta con más profundidad con la ayuda de un ejemplo. Supongamos que el productor de bloques Alice construye un bloque B con transacciones tx1, tx2, ..., txn. Supongamos que tx1 es una transacción maliciosa. Si se transmite tx1, cualquier nodo completo puede verificar que es malicioso y enviarlo al cliente ligero, que sabe de inmediato que el bloqueo es inaceptable. Sin embargo, si Alice quiere ocultar tx1, mostrará el encabezado y todos los datos de la transacción excepto tx1. El nodo completo no puede verificar la corrección de tx1. Deje que los nodos ligeros consulten cualquier transacción, de manera uniforme y aleatoria. Un cliente ligero consulta tx1 con probabilidad 1n. Por lo tanto, Alice puede engañar a los clientes ligeros para que acepten transacciones maliciosas con una probabilidad abrumadora. Debido a la naturaleza no imputable, los nodos completos no pueden probar de ninguna manera que tx1 no está disponible.
Entonces, ¿qué debemos hacer?
La solución a este problema consiste en introducir redundancia en los bloques. En general, existe una gran cantidad de literatura sobre la teoría de la codificación, y la codificación de borrado en particular, que puede ayudarnos a abordar este problema.
En resumen, la codificación de borrado nos permite expandir cualquier n bloques de datos en 2 bloques de datos, donde cualquiera de los 2n bloques de datos es suficiente para reconstruir el bloque de datos original (los parámetros son ajustables, pero para simplificar, consideramos esto aquí).
Si forzamos a los productores de bloques a borrar el código de las transacciones tx1, tx2, ..., txn, y luego ocultamos las transacciones individuales, entonces se deben ocultar n+1 transacciones, ya que cualquier transacción es suficiente para construir todo el conjunto de transacciones. En este caso, un número constante de consultas brinda a los clientes ligeros la confianza suficiente de que los datos subyacentes están realmente disponibles.
Vaya, ¿eso es todo?
No. Si bien este simple truco hace que la ocultación sea mucho más difícil, aún es posible que los productores de bloques realicen intencionalmente la codificación de borrado de manera incorrecta. Sin embargo, un nodo completo puede verificar que esta codificación de borrado se haya realizado correctamente y, de no ser así, puede demostrarlo a los clientes ligeros. Esto se conoce como prueba de fraude. Curiosamente, un cliente ligero necesita tener un vecino de nodo completo honesto para asegurarse de que si está codificado incorrectamente, recibirá una prueba de fraude. Esto asegura que los clientes ligeros accedan a cadenas libres de transacciones maliciosas con una probabilidad muy alta.
¡Pero hay un problema! Si se implementa de forma sencilla, el tamaño de las pruebas de fraude se puede ordenar por el tamaño del propio bloque. Pero nuestros ajustes preestablecidos de recursos para clientes ligeros nos prohíben usar ese diseño. Se pueden lograr mejoras en este sentido mediante el uso de técnicas de codificación de borrado multidimensional, que reducen el tamaño de las pruebas de fraude a un tamaño aceptable. Para abreviar, no los cubrimos, pero este documento (https://arxiv.org/abs/1809.09044) los analiza en detalle.
El problema de las soluciones basadas en pruebas de fraude es que un cliente ligero nunca puede estar completamente seguro de ningún bloque para el que no haya recibido una prueba de fraude. Además, siempre han confiado en que sus compañeros de nodo completo sean honestos. También debe haber un incentivo para que los nodos honestos sigan auditando bloques constantemente.
¿Hay alguna forma de evitar las pruebas de fraude?
Recientemente, los compromisos de vectores han atraído una atención renovada al espacio blockchain. Estos compromisos vectoriales, especialmente los compromisos KZG/Kate de tamaño constante con polinomios, se pueden utilizar para diseñar esquemas DA sucintos sin pruebas de fraude. En resumen, las promesas de Kate nos permiten comprometer polinomios con un solo elemento de grupo. Además, este esquema nos permite probar que en algún punto i usando testigos de tamaño constante, la evaluación del polinomio es (i). Los esquemas de compromiso están ocultos y vinculados computacionalmente, así como homomórficos, lo que nos permite evitar claramente las pruebas de fraude.
Obligamos a los productores de bloques a tomar datos de transacciones sin procesar y organizarlos en una matriz bidimensional de tamaño n,m. Expande cada columna de tamaño n en columnas de tamaño 2n mediante interpolación polinomial. Para cada fila de esta matriz de extensión, genera un compromiso polinomial y envía estos compromisos como parte del encabezado del bloque. A continuación se muestra un diagrama esquemático del bloque.
Un cliente ligero consulta cualquier celda de esta matriz extendida en busca de un testigo, lo que le permite verificarlo inmediatamente con el encabezado del bloque. Las pruebas de membresía de tamaño constante hacen que el muestreo sea muy eficiente. La naturaleza homomórfica de las promesas garantiza que las pruebas solo se verifiquen si el bloque se construye correctamente, y la interpolación polinomial garantiza que un número constante de muestras satisfactorias significa que los datos están disponibles con una probabilidad muy alta.
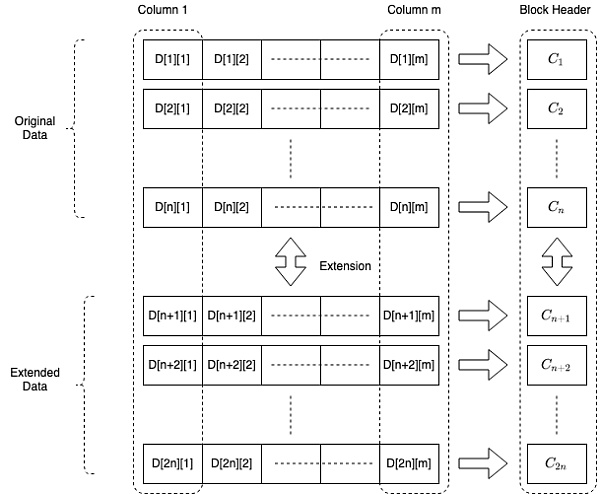
Los detalles más finos de este esquema y una mayor optimización y estimación de costos están más allá del alcance de este documento.
¿Cuáles son las otras opciones y cuáles son los cambios adicionales?
Los códigos de borrado de dimensiones superiores y el compromiso de Kate no son las únicas soluciones al problema del DA. Omitimos otros métodos aquí, como los árboles Merkle codificados, los árboles intercalados codificados, los métodos basados en FRI y STARK, pero cada uno tiene sus ventajas y desventajas.
Nosotros, en Polygon, hemos estado usando Kate Commitment para desarrollar soluciones de disponibilidad de datos. En un artículo posterior, cubriremos los detalles de implementación, cómo puede usarlo hoy y cómo estamos trabajando para transformar el espacio del problema DA.
Tags:
El título original: "Cumbre financiera de Phoenix.com (verano) 2021 y Tianlai Sixianghui: Siete palabras clave para romper la situación y resolver confusiones" 2021 está destinado a ser un año extraordinario.
Golden Weekly es una columna de resumen semanal de la industria de blockchain lanzada por Golden Finance, que cubre noticias clave, información sobre minería, tendencias de proyectos.
La palabra original en inglés "Metaverse" proviene de la novela de ciencia ficción "Avalanche" de Neil Stephenson de 1992. En esta novela.
En esta publicación, profundizamos en los detalles del problema de disponibilidad de datos y cómo afecta la escala de Ethereum. ¿Cuáles son los problemas de disponibilidad de datos? El problema de disponibilidad de da.
El 25 de junio, este viernes, vencerán la friolera de $4 mil millones en opciones.De acuerdo con las estadísticas de Deribit, entre las opciones de vencimiento de $ 4 mil millones.
¡HOLA~ Amigos! Usted ha escuchado a menudo la palabra "Metaverso" recientemente. Muchos amigos se sienten muy extraños con este concepto, y se sienten un poco misteriosos al tratar de entenderlo.De hecho.
La innovación de la tecnología blockchain no solo dio origen a varias monedas digitales encriptadas.



