






 BTC/USD-2.22%
BTC/USD-2.22% ETH/USD-3.26%
ETH/USD-3.26% LTC/USD-2.4%
LTC/USD-2.4% DOT/USD-3.53%
DOT/USD-3.53% ADA/USD-3.2%
ADA/USD-3.2% SOL/USD-3.14%
SOL/USD-3.14% XRP/USD-2.16%
XRP/USD-2.16% DOGE/US-4.56%
DOGE/US-4.56%Los modelos de aprendizaje automático tienden a sobreajustarse cuando se usan con conjuntos de datos de blockchain. ¿Qué es el overfitting y cómo solucionarlo?
A primera vista, la idea de usar el aprendizaje automático para analizar conjuntos de datos de blockchain suena muy atractiva, pero es un camino desafiante. Entre estos desafíos, la falta de conjuntos de datos etiquetados sigue siendo el mayor desafío a superar al aplicar métodos de aprendizaje automático a conjuntos de datos de blockchain. Estas limitaciones hacen que muchos modelos de aprendizaje automático operen con muestras de datos muy pequeñas para entrenar y optimizar en exceso esos modelos que causan el fenómeno de sobreajuste. Hoy, quiero profundizar en el desafío del sobreajuste en el análisis de blockchain y sugerir algunas soluciones.
El sobreajuste se considera uno de los mayores desafíos en las aplicaciones modernas de aprendizaje profundo. Conceptualmente, el sobreajuste ocurre cuando un modelo genera hipótesis que se adaptan demasiado bien a las de un conjunto de datos en particular para adaptarse a nuevos conjuntos de datos. Una analogía útil para comprender el sobreajuste es pensar en él como una ilusión en el modelo. Esencialmente, el modelo alucina/sobreajusta cuando infiere suposiciones incorrectas del conjunto de datos. Se ha escrito mucho sobre el sobreajuste desde los primeros días del aprendizaje automático, por lo que no creo que haya una forma inteligente de explicarlo. Para los conjuntos de datos de blockchain, el sobreajuste es un resultado directo de la falta de datos etiquetados.
Las cadenas de bloques son grandes estructuras de datos semianónimas en las que todo se representa mediante un conjunto común de construcciones, como transacciones, direcciones y bloques. Desde este punto de vista, hay información mínima para probar el registro de blockchain. ¿Es una transacción de transferencia o de pago? ¿Es esta la dirección de una billetera de inversionista personal o una billetera fría de intercambio? Estos calificadores son cruciales para los modelos de aprendizaje automático.
Imagine que estamos creando un modelo para detectar direcciones de intercambio en un conjunto de cadenas de bloques. Este proceso requiere que entrenemos el modelo utilizando un conjunto de datos existente de direcciones de blockchain, que todos sabemos que no es muy común. Si usamos un pequeño conjunto de datos de EtherScan u otras fuentes, el modelo podría sobreajustarse y hacer clasificaciones incorrectas.
Fang Xiao: Usando blockchain y otras tecnologías para transformar productos y servicios, las instituciones financieras realmente pueden brindar asistencia para el desarrollo de nuevas empresas de infraestructura: el 18 de diciembre, Fang Xiao, vicepresidente de HSBC China y director de finanzas industriales y comerciales, dijo: Solo mediante la adopción continua de nuevas tecnologías financieras, utilizando las últimas tecnologías, como plataformas de banca digital, IA y blockchain, para realizar cambios en productos, servicios y procesos, las instituciones financieras pueden realmente brindar asistencia para el desarrollo de nuevas empresas de infraestructura. (Revista financiera cuenta pública) [2020/12/18 15:43:01]
Uno de los aspectos que hace que el sobreajuste sea tan desafiante es que es difícil generalizar a través de diferentes técnicas de aprendizaje profundo. Las redes neuronales convolucionales tienden a desarrollar patrones de sobreajuste que son diferentes de los observados para las redes neuronales recurrentes que los modelos generativos, y este patrón puede extrapolarse a cualquier tipo de modelo de aprendizaje profundo. Irónicamente, la tendencia al sobreajuste aumenta linealmente con el poder computacional de los modelos de aprendizaje profundo. Dado que los agentes de aprendizaje profundo pueden generar hipótesis complejas casi gratis, la posibilidad de sobreajuste aumenta.
El sobreajuste es un desafío constante en los modelos de aprendizaje automático, pero cuando se trabaja con conjuntos de datos de blockchain, es casi un hecho. La respuesta obvia al sobreajuste es usar un conjunto de datos de entrenamiento más grande, pero esta no siempre es una opción. En IntoTheBlock, a menudo nos enfrentamos al desafío del sobreajuste y confiamos en una serie de métodos básicos para resolver el problema.
Tres estrategias simples para combatir el sobreajuste en conjuntos de datos de blockchain
La primera regla general contra el sobreajuste es reconocerlo. Si bien no existe una bala de plata para evitar el sobreajuste, la experiencia práctica ha demostrado que algunas reglas simples, casi de sentido común, pueden ayudar a prevenir este fenómeno en las aplicaciones de aprendizaje profundo. Para evitar el sobreajuste, se han publicado decenas de mejores prácticas, que contienen tres conceptos básicos.
OKB superó la marca de $ 5,8: los datos de OKEx muestran que OKB ha subido a corto plazo y superó la marca de $ 5,8, y ahora cotiza a $ 5,801, un aumento intradiario del 5,2 %. El mercado fluctúa mucho, así que haga un buen trabajo. en el control de riesgos. [2020/9/1]
Proporción de datos/supuestos
El sobreajuste generalmente ocurre cuando un modelo genera demasiadas hipótesis sin los datos correspondientes para probarlas. Por lo tanto, las aplicaciones de aprendizaje profundo deben tratar de mantener una proporción adecuada entre el conjunto de datos de prueba y la hipótesis que debe evaluarse. Sin embargo, esto no siempre es una opción.
Hay muchos algoritmos de aprendizaje profundo (como el aprendizaje inductivo) que se basan en la generación continua de hipótesis nuevas, a veces más complejas. En estos casos, existen algunas técnicas estadísticas que pueden ayudar a estimar el número de hipótesis correctas para optimizar las posibilidades de encontrar una que se acerque a la correcta. Aunque este método no puede proporcionar una respuesta exacta, puede ayudar a mantener una relación estadísticamente equilibrada entre el número de hipótesis y la composición del conjunto de datos. El profesor de Harvard Leslie Valiant explica brillantemente este concepto en su libro "Probably Right".
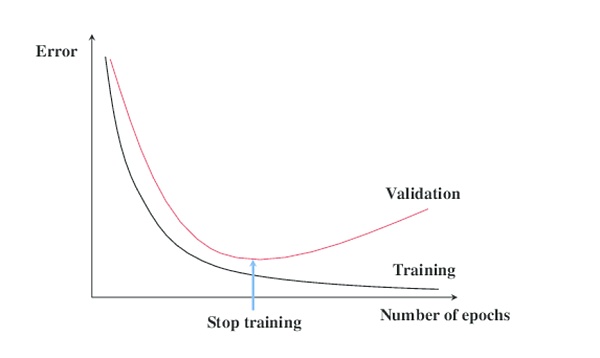
La relación datos/hipótesis es muy evidente cuando se realiza un análisis de blockchain. Supongamos que estamos construyendo un algoritmo predictivo basado en un año de transacciones de blockchain. Debido a que no estábamos seguros de qué modelo de aprendizaje automático probar, utilizamos un enfoque de búsqueda de arquitectura neuronal (NAS) que probó cientos de modelos contra un conjunto de datos de blockchain. Suponiendo que el conjunto de datos contiene solo un año de transacciones, el enfoque NAS puede producir un modelo que se ajuste perfectamente al conjunto de datos de entrenamiento.
Admite suposiciones simples
Una idea conceptualmente trivial pero técnicamente difícil para evitar que los modelos de aprendizaje profundo se ajusten en exceso es generar continuamente hipótesis más simples. ¡seguramente! Lo simple siempre es mejor, ¿no es así? Pero, ¿cuál es una suposición más simple en el contexto de los algoritmos de aprendizaje profundo? Si necesitamos reducir esto a un factor cuantitativo, diría que la cantidad de atributos en una hipótesis de aprendizaje profundo es directamente proporcional a su complejidad.
Las hipótesis simples suelen ser más fáciles de evaluar que otras hipótesis con fuertes propiedades computacionales y cognitivas. Por lo tanto, los modelos más simples generalmente son menos propensos al sobreajuste que los modelos complejos. Ahora, la siguiente pieza obvia del rompecabezas es descubrir cómo generar hipótesis más simples en modelos de aprendizaje profundo. Una técnica menos obvia es adjuntar algún tipo de penalización al algoritmo en función de la complejidad estimada. El mecanismo tiende a favorecer suposiciones más simples y aproximadamente precisas sobre suposiciones más complejas (ya veces más precisas) que pueden fallar cuando se dispone de nuevos conjuntos de datos.
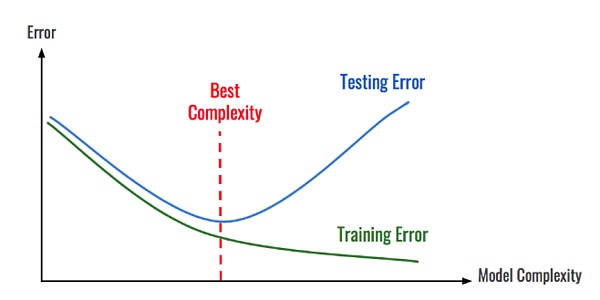
Para explicar esta idea en el contexto del análisis de la cadena de bloques, imaginemos que estamos construyendo un modelo para clasificar las transacciones de pago en una cadena de bloques. El modelo utiliza una red neuronal profunda compleja que genera 1000 características para realizar la clasificación. Si se aplica a una cadena de bloques más pequeña como Dash o Litecoin, lo más probable es que el modelo se sobreajuste.
Balance de sesgo/varianza
El sesgo y la varianza son dos estimadores clave en los modelos de aprendizaje profundo. Conceptualmente, el sesgo es la diferencia entre la predicción promedio del modelo y el valor correcto que estamos tratando de predecir. Un modelo con alto sesgo presta poca atención a los datos de entrenamiento, lo que simplifica el modelo. Siempre da como resultado una alta tasa de error tanto en los datos de entrenamiento como de prueba. Alternativamente, la varianza se refiere a la variabilidad de las predicciones del modelo para un punto de datos dado o un valor que nos informa sobre la distribución de los datos. Un modelo con una varianza alta pone mucha atención en los datos de entrenamiento y no logra generalizar a datos que nunca antes había visto. Como resultado, dichos modelos funcionan bien con los datos de entrenamiento, pero tienen altas tasas de error con los datos de prueba.
¿Cómo se relacionan el sesgo y la varianza con el sobreajuste? En términos súper simples, el arte de la generalización se puede generalizar reduciendo el sesgo de un modelo sin aumentar su varianza. Una buena práctica en el aprendizaje profundo es modelarlo para comparar periódicamente las hipótesis resultantes con un conjunto de datos de prueba y evaluar los resultados. Si la hipótesis continúa arrojando el mismo error, tenemos un gran problema de sesgo y necesitamos ajustar o reemplazar el algoritmo. Por el contrario, si no hay un patrón claro de errores, el problema es una discrepancia y necesitamos más datos.
En resumen
• Cualquier modelo de baja complejidad: propenso a fallar debido al alto sesgo y la baja varianza.
• Cualquier modelo de alta complejidad (red neuronal profunda): propenso al sobreajuste debido al bajo sesgo y la alta varianza.
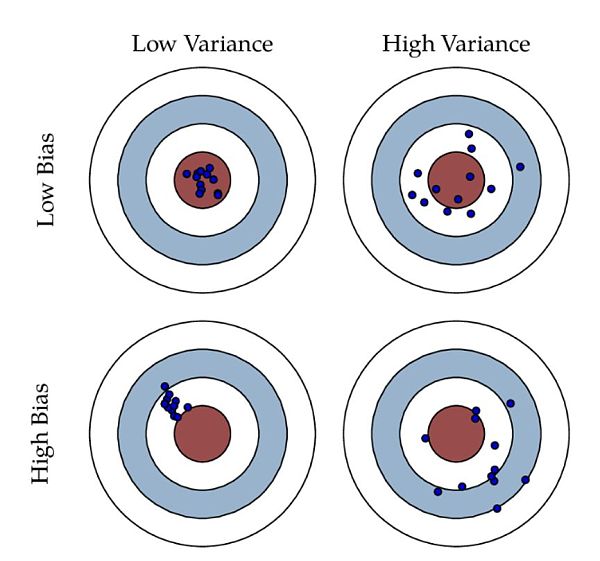
En el contexto del análisis de la cadena de bloques, la fricción entre la variación y el sesgo está en todas partes. Volvamos a nuestro algoritmo, que intenta predecir el precio utilizando muchos factores de blockchain. Si usáramos métodos de regresión lineal simple, el modelo podría no ser apropiado. Sin embargo, si usamos una red neuronal ultracompleja con un conjunto de datos pequeño, el modelo puede sobreajustarse.
El uso del aprendizaje automático para analizar datos de blockchain es un espacio incipiente. Como resultado, la mayoría de los modelos sufren los desafíos tradicionales en las aplicaciones de aprendizaje automático. Fundamentalmente, el sobreajuste es uno de los desafíos omnipresentes en el análisis de blockchain debido a la falta de datos etiquetados y modelos bien entrenados
Tags:
El 18 de enero se llevó a cabo en Beijing la Conferencia Nacional de Presidentes de Tribunales Superiores. La reunión señaló que es necesario profundizar integralmente la construcción de tribunales inteligentes.
Recientemente, el proyecto de privacidad Origo.Network anunció que ha llegado a una cooperación con QIWI Blockchain Technologies, la empresa de cadenas de bloques del gigante de pagos ruso QIWI.
El 28 de enero de 2020, el equipo de Hoo anunció que para apoyar la prevención y el tratamiento de la nueva neumonía por coronavirus.
Los modelos de aprendizaje automático tienden a sobreajustarse cuando se usan con conjuntos de datos de blockchain. ¿Qué es el overfitting y cómo solucionarlo?A primera vista.
Beneficios: ¡Exquisitos premios te esperan por participar en la interacción de mensajes al final del artículo!Durante el Festival de Primavera del año pasado.
Una de las características más críticas de la tecnología blockchain es su naturaleza descentralizada. Esto significa que su información es compartida por todas las partes de la red. Por lo tanto.
Con la economía de EE. UU. mostrando signos de debilidad, especialmente con las tasas de interés cerca de mínimos históricos, muchos grandes bancos, incluido JPMorgan Chase.



