






 BTC/USD-2.22%
BTC/USD-2.22% ETH/USD-3.26%
ETH/USD-3.26% LTC/USD-2.4%
LTC/USD-2.4% DOT/USD-3.53%
DOT/USD-3.53% ADA/USD-3.2%
ADA/USD-3.2% SOL/USD-3.14%
SOL/USD-3.14% XRP/USD-2.16%
XRP/USD-2.16% DOGE/US-4.56%
DOGE/US-4.56%¿Qué es la cadena de bloques? ¿Qué es una base de datos distribuida? Creo que mucha gente tiende a confundir estos dos conceptos. En la superficie, la base de datos distribuida y no manipulable creada por la cadena de bloques tiene muchas similitudes con la base de datos distribuida tradicional en términos de tecnología básica, pero solo es similar.
En lo que respecta al almacenamiento distribuido, ambos tienen datos de respaldo redundantes, pero aún existen diferencias esenciales en los propósitos técnicos. El propósito central de las bases de datos distribuidas tradicionales es construir un centro lógico tanto como sea posible, que pueda proporcionar servicios escalables, de bajo costo y de alto rendimiento al mundo exterior. El propósito principal de usar estas tecnologías en la cadena de bloques es construir un mundo distribuido donde la propiedad de los datos esté permanentemente protegida y los datos puedan compartirse libremente.
Además, existe una gran diferencia entre los dos en términos de seguridad de datos, credibilidad y métodos de gobierno. Pero antes de comenzar con la interpretación específica, volvamos al historial de desarrollo de la base de datos para comprender mejor la innovación provocada por la base de datos distribuida de blockchain.
En realidad, las bases de datos son un tema muy antiguo. Las bases de datos, tal como las conocemos hoy, se remontan a la década de 1950; sin embargo, la necesidad humana de almacenar y organizar datos es anterior a eso.
Además de las pinturas rupestres históricamente conocidas y las tabletas de arcilla raras, se cree que el Museo de Ugaritic (la ciudad en la actual Siria) es el primer esfuerzo humano integral para documentar el almacenamiento de datos, donde se encuentra una gran cantidad de tabletas de arcilla y documentos de Textos diplomáticos y literatura del siglo XII a.C. Pero esto también solo registra el trabajo de recopilación de datos, no la recopilación de datos. Los esfuerzos para recopilar los datos están atestiguados objetivamente en el Museo del Foro. Sin embargo, esta rica historia es solo una gota en el océano.
Director ejecutivo de MicroStrategy: se contactó con Musk sobre el uso de energía: el director ejecutivo de MicroStrategy, la empresa de inteligencia empresarial, Michael Saylor, dijo que se puso en contacto con el director ejecutivo de Tesla, Elon Musk, sobre el uso de energía. El enfoque ahora está en la mejor manera de informar el uso de energía. Se reunirá con los mineros de bitcoin. (Diez de oro) [2021/5/26 22:44:12]
En el siglo XVIII, la aparición de fichas se considera el antecesor de las bases de datos informáticas. El naturalista Carl Linnaeus introdujo un sistema de registros taxonómicos en ese momento, donde cada especie se colocaba en una hoja de papel separada. Con él, los registros relevantes se pueden organizar y complementar fácilmente. Pero la ficha tiene una gran desventaja: debe ser registrada y procesada por una persona, lo cual es muy engorroso.
Por lo tanto, en 1890, el estadístico estadounidense Herman Hollerith inventó una máquina contadora para satisfacer las necesidades de los departamentos gubernamentales en el censo. Esta máquina utilizaba tarjetas perforadas para almacenar información y fue el primer procesamiento electromecánico de datos realizado por humanos. En 1911, Herman formó una empresa de computación y tabulación, que pasó a llamarse "International Business Machines Corporation" en 1924, que es la mundialmente famosa American IBM Corporation.
CEO de MicroStrategy: Bitcoin es el activo más escaso: El CEO de MicroStrategy, Michael Saylor, dice que Bitcoin es el activo más escaso. (Diez de oro) [9/2/2021 19:16:59]

Y antes de la Segunda Guerra Mundial, Estados Unidos instituyó la obligación de registrar los números de seguridad social de los empleados. A pedido de la oficina, IBM construyó una nueva máquina, la UNIVAC I, que se utilizó en los censos a partir de 1951. También fue la primera computadora digital producida en masa para uso comercial y ocupa un lugar especial en la historia de la computación.
En 1960, las bases de datos dieron paso a los lenguajes de programación y comenzaron a establecerse bases de datos computarizadas. El uso de computadoras era una opción más rentable para las organizaciones privadas en ese momento. La década siguiente dio origen a dos modelos de datos populares:
Uno es un modelo de red llamado CODASYL;
Otro es un modelo en capas conocido como IMS.
Luego, con la introducción del álgebra, el cálculo relacional y la terminología comprensible, comenzó la creación del lenguaje de consulta estructurado (SQL), la característica principal de estos sistemas de bases de datos es almacenar datos estructurados. Pero a principios de siglo, hubo un cambio en la forma en que las personas pensaban sobre los datos, y estaba surgiendo una frontera de aplicaciones construidas sobre objetos y modelos de datos estructurados. Esto ha resurgido el concepto de bases de datos no estructuradas (NoSQL).

En resumen, la tecnología de bases de datos en sí está en constante evolución. Cómo elegir un almacenamiento de datos adecuado es una condición necesaria para el funcionamiento fluido y eficaz de un programa de aplicación, y también es una condición necesaria para utilizar la tecnología adecuada para procesar datos. Con la actualización continua de las necesidades reales, la base de datos también está en constante desarrollo. Podemos resolver bien el problema de escalabilidad del almacenamiento de datos y el acceso a datos a través de NoSQL, y resolver el problema del procesamiento masivo de datos de Internet a través de tecnologías como el almacenamiento en la nube.
Pero surge la siguiente pregunta, que es cómo resolver el problema de la autenticidad y validez de los datos de forma escalable.
Las bases de datos distribuidas se producen en el contexto de Internet para manejar grandes volúmenes de datos y solicitudes distribuidas.Bajo control centralizado, se supone que cada nodo es honesto, de modo que múltiples nodos mantienen conjuntamente una base de datos distribuida lógicamente integrada. Podemos ver que la capa de datos de blockchain es diferente de las bases de datos distribuidas tradicionales en la lógica subyacente al encapsular bloques de datos subyacentes y datos y algoritmos básicos, como algoritmos de cifrado y marcas de tiempo.
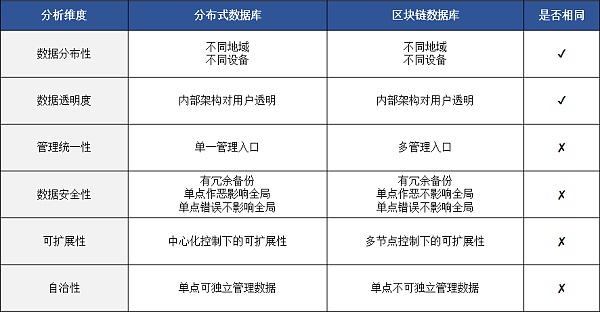
El primero es la distribución de datos: aunque los datos se almacenan en diferentes dispositivos, bajo la arquitectura cliente-servidor de las bases de datos tradicionales, la organización central puede controlar y programar uniformemente cada nodo para que participe en el cálculo, y el usuario (o cliente) Los datos almacenados en el servidor puede ser modificado. En la capa de datos de la cadena de bloques, la información se almacena de manera distribuida entre los nodos y ningún nodo puede controlar la formación de los datos del libro mayor. Solo a través de la coordinación entre los nodos se puede generar un libro mayor coherente.
El segundo es la seguridad de los datos: cuando se utiliza el almacenamiento distribuido tradicional, es posible que se encuentre con el problema de la búsqueda y manipulación de los datos. Una vez que se falsifica la información de los datos, causará graves pérdidas a los clientes. La capa de datos de la cadena de bloques es una estructura de cadena que comienza en el bloque de génesis e incluye los datos del bloque de la cadena de bloques, la estructura de la cadena y el número aleatorio, la marca de tiempo, la clave pública y los datos de la clave privada en el bloque. Espere. Cada bloque está relacionado entre sí por la firma Hash. Si una determinada transacción en el bloque cambia, su valor Hash también cambiará. Al comparar con los datos de otros nodos, se puede encontrar la identidad del "nodo malicioso". Marcas de cambio . Por lo tanto, esta estructura de almacenamiento de datos no solo respalda la manipulación y la trazabilidad, sino que también garantiza la apertura y la transparencia del proceso de registro de datos, así como la protección de la privacidad de los datos confidenciales después de que se cargan en la cadena.
Finalmente, la confiabilidad de los datos: con la seguridad del procesamiento de datos, las empresas no solo pueden confiar en los datos compartidos entre las empresas con las que cooperan, sino también en los datos compartidos por los competidores. Esto crea oportunidades para que más jugadores en la vertical se unan a la red blockchain y aumenten la visibilidad de los datos.
A través del almacenamiento de datos de múltiples nodos y datos de cifrado de algoritmos, la capa de datos de la cadena de bloques crea un sistema de confianza subyacente. Pero cómo lograr la difusión y comunicación entre pares de estos datos, seguiremos hablando de ello en el próximo número de "Capa de red".
Tags:
YFV es un proyecto DeFi basado en Ethereum.Hoy temprano.
Después de experimentar una montaña rusa extremadamente rápida, el protocolo DeFi Yam Finance (en adelante, Yam), que es popular en el círculo de divisas con la imagen de "boniato".
Hoy, Zeus Capital publicó un artículo sobre la reducción de LINK.
¿Qué es la cadena de bloques? ¿Qué es una base de datos distribuida? Creo que mucha gente tiende a confundir estos dos conceptos. En la superficie.
BTC rompió efectivamente la marca de 12,000 enteros. A lo largo del mercado histórico, cada vez que Bitcoin se reduce a la mitad.
Cualquiera que haya experimentado el desarrollo de Internet e Internet móvil sabe la importancia del sistema operativo. En la era de las PC.
El artículo es una contribución de Biquan Beiming, columnista de Jinse Finance and Economics, y sus comentarios solo representan sus puntos de vista personales.



