






 BTC/USD-2.22%
BTC/USD-2.22% ETH/USD-3.26%
ETH/USD-3.26% LTC/USD-2.4%
LTC/USD-2.4% DOT/USD-3.53%
DOT/USD-3.53% ADA/USD-3.2%
ADA/USD-3.2% SOL/USD-3.14%
SOL/USD-3.14% XRP/USD-2.16%
XRP/USD-2.16% DOGE/US-4.56%
DOGE/US-4.56% 
El "tiempo" es un tema eterno en los tiempos cambiantes. Se han producido debates sobre el tiempo en blockchains y otros sistemas distribuidos. El tiempo conecta procesos y nodos, y también usamos la "granularidad" del tiempo para medir la red descentralizada que conecta bloques en cadenas.
La dificultad del tiempo en un sistema distribuido es que es difícil que los "relojes físicos" de diferentes participantes coincidan completamente. El maestro del sistema distribuido Lamport proporciona un método descentralizado, transformando el problema en la relación entre el tiempo y el orden, y presenta el concepto de reloj lógico, al igual que la introducción de un "reloj biológico" para los sistemas distribuidos, incluida la cadena de bloques.
stakefish compila un artículo del analista de Vac y desarrollador de ENS, Dean Eigenmann, que presenta la discusión de Lamport sobre el tiempo, los relojes y el orden, y recuerda a todos que deben comprender la cadena de bloques y el tiempo del sistema distribuido desde otra perspectiva.

¿Qué tema es más apropiado para iniciar una serie de artículos sobre sistemas distribuidos? ¿Protocolo de transacciones de privacidad de Ethereum AZTEC? ¿El algoritmo de Paxos, que es notoriamente difícil de dominar? Estos temas se dejan para ser escritos más adelante. Hoy elegí un tema básico como inicio: el tema del tiempo en los sistemas distribuidos.
Este artículo interpreta el conocido artículo "Tiempo, relojes y el orden de los eventos en un sistema distribuido" de la ganadora del Premio Turing y gurú de la informática Leslie Lamport. Es divertido volver a leer esta publicación mucho tiempo después y destilar los conceptos clave.
Los amigos que no estén familiarizados con Leslie Lamport pueden hacerse una idea general. Es famoso por crear LaTeX, TLA+, Paxos y también analiza el problema general bizantino. Y por supuesto el reloj Lamport (el primer reloj lógico), cuyos conceptos básicos también introduciremos en este artículo.

Veamos primero la definición de un sistema distribuido. La definición dada por Lamport es esta:
"Un sistema se denomina sistema distribuido si la demora en la entrega de información dentro del sistema no es despreciable en comparación con el tiempo entre eventos en un solo proceso".
Me gusta esta definición porque se enfoca en la demora entre enviar y recibir un mensaje.
El volumen de operaciones del fin de semana de la versión Ethereum del protocolo de liquidez multicadena LuaSwap fue de casi 800 000 dólares estadounidenses: El protocolo de liquidez multicadena LuaSwap tuiteó que (solo para la versión Ethereum) el volumen de operaciones del fin de semana fue de casi 800 000 dólares estadounidenses, y los fanáticos de Twitter alcanzaron 4.000. Según los informes a fines de enero, LuaSwap anunció oficialmente que comenzó a ejecutarse en TomoChain. [2021/2/8 19:11:49]
Con la definición claramente definida, comenzamos la introducción formal.
Ordenar eventos localmente no podría ser más fácil. Simplemente asigne a cada evento una marca de tiempo cuando sucedió. Podemos obtener el orden general de todos los eventos, lo que significa que todos los eventos se pueden organizar en un orden específico.
Pero este problema es mucho más difícil en el contexto de los sistemas distribuidos. ¿por qué?
Todo debido a la naturaleza muy simple de un sistema distribuido: después de enviar un mensaje entre nodos, puede llegar 0, 1 o más veces en cualquier punto en el futuro. En este caso, los distintos nodos del sistema distribuido no pueden ponerse de acuerdo sobre la hora. por ejemplo:
Un nodo puede enviar un mensaje a otro nodo para marcar la hora actual como las 12:00:00, pero el receptor no sabe cuánto tardó en enviarse el mensaje, por lo que no hay forma de confirmar si aún son las 12:00: 00 cuando llega. Si es así, no hay forma de determinar si la información está sincronizada, incluso si los mensajes se envían de ida y vuelta durante un día entero entre los nodos. Si no podemos ponernos de acuerdo sobre el tiempo, no podemos ponernos de acuerdo sobre la secuencia de eventos.
Entonces, ¿cómo resolver este problema?
En un sistema distribuido, múltiples nodos se comunican enviándose mensajes entre sí. Cuando el nodo recibe la información, primero la confirma y luego ejecuta su próximo evento. Tal orden muestra originalmente una "relación causal": la información debe enviarse antes de que pueda recibirse.
Anotación: Esta relación causal es una relación secuencial, no una relación lógica entre causa y efecto.
Entonces el orden puede trazarse en base a la relación de causalidad: el mensaje debe ser enviado antes de que sea recibido por él. Con solo mirar los dos eventos A y B, podemos describir el orden dando la relación de "sucede antes".
Ahora bien, esta relación puede identificarse sin una noción sistemática del tiempo físico: el evento A debe haber sucedido antes que el evento B si A tuvo un efecto causal sobre B. La causalidad nos permite determinar el orden de los eventos relacionados en un sistema, un orden parcial.
El ordenamiento parcial también tiene una limitación: sin poder determinar las dependencias, es posible que no sepamos el orden exacto de cada evento en el sistema. Debido a que puede haber muchos eventos simultáneamente en todo el sistema, no todos los nodos son conscientes de la ocurrencia de estos eventos.
Reloj
Pero ahora que tenemos un orden parcial, podemos agregar un reloj al sistema para obtener el orden total de todos los eventos en el sistema.
Recién ahora sabemos que no es factible usar relojes físicos en sistemas distribuidos, entonces necesitamos usar relojes lógicos. Un reloj lógico es esencialmente una función capaz de asignar un número a un evento. Este número representa cuándo sucedió el evento (de ahora en adelante nos referiremos a este número como tiempo), y no tiene relación con el tiempo físico.
Suponemos que cada nodo en este sistema distribuido tiene un reloj. Este reloj avanza a medida que se ejecutan los eventos, pero el progreso del reloj no se considera un evento en el sistema. Para cada evento que ocurre en un nodo del sistema, el reloj lógico asigna un número al evento. Con base en esta suposición, podemos satisfacer las siguientes condiciones de reloj:
∀a,b a → b ⟹ C(a) <C(b)
¿Qué significa la expresión anterior?
La flecha "→" significa "sucedió antes (sucedió antes)", y C representa la función del reloj, que puede entenderse simplemente como tiempo. Entonces, para expresar el significado es: para cada evento a, b, si a ocurre antes de b, entonces el tiempo de a es menor que el tiempo de b.
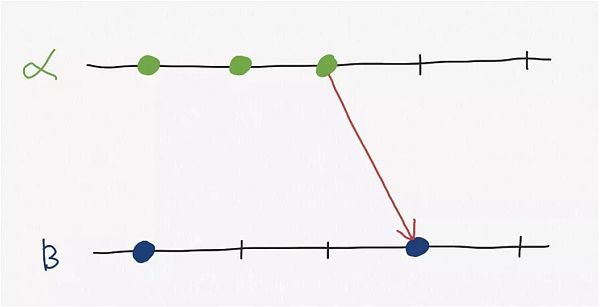
Pero la deducción inversa no es cierta, solo porque el tiempo de un evento es menor que el tiempo de otro evento, no se puede decir que este evento sucedió antes, pueden ser concurrentes.
En la imagen de arriba, podemos ver que en el nodo α, ocurrió un evento en el tiempo 1 y el tiempo 2 respectivamente; el nodo β tiene un evento ocurrido en su propio tiempo 1. Los eventos en el tiempo 1 y el tiempo 2 en el nodo α son concurrentes con los eventos en el tiempo 1 en el nodo β y no tienen una conexión causal.
Si a y b son dos eventos en un solo nodo, y a ocurre antes que b, entonces el tiempo de a debería ser menor que el tiempo de b.
Si a es un nodo que envía un mensaje yb es otro nodo que recibe un mensaje, entonces el tiempo de a debería ser menor que el tiempo de b.
Los nodos necesitan dejar que el reloj marque entre eventos. De lo contrario, el reloj debe adelantarse a una hora posterior a la contenida en los mensajes recibidos de otros nodos. b puede suceder después de que el reloj se ajuste rápido.
Ahora bien, podemos usar relojes que cumplan con estas condiciones para establecer una secuencia general de todo el sistema distribuido, aquí simplemente ordenamos según el tiempo dado por los relojes de cada evento.
Caso de uso
Finalmente configuramos una máquina de estado para ver el uso del reloj lógico. Por ejemplo, tenemos un sistema distribuido en el que varios nodos quieren acceder a los recursos compartidos y solo se puede acceder a un nodo a la vez. La máquina de estado debe cumplir las siguientes condiciones:
Condición 1: un nodo que puede acceder a un recurso primero debe liberar el recurso antes de que otros nodos puedan acceder a él.
Condición 2: Las solicitudes de recursos deben tener acceso en el orden en que se realizan las solicitudes.
Condición 3: si cada nodo al que se le concede acceso finalmente libera el recurso, todas las solicitudes se concederán finalmente.
¿Por qué no introducir un coordinador intermedio? Porque en este caso, si ocurre una solicitud anterior pero llega más tarde, la condición 2 no se puede cumplir; otra razón es que queremos adoptar una solución descentralizada.
Así que todavía tenemos que crear condiciones para cumplir con este reloj lógico. ¿Cómo cumplir las condiciones?
Lamport nos proporciona una solución descentralizada. Primero, queremos que todos los nodos almacenen una cola de solicitudes. En segundo lugar, se deben satisfacer algunas suposiciones simples:
Suposición 1: Todos los mensajes se reciben en el orden en que se enviaron.
Supuesto 2: todos los mensajes finalmente se reciben.
Suposición 3: cada nodo puede enviar mensajes directamente a todos los demás nodos del sistema.
Si existen algoritmos y protocolos más complejos, se pueden ignorar las suposiciones anteriores.
Ahora podemos definir un algoritmo que satisfaga estas 3 condiciones y mostrar la funcionalidad del reloj en la práctica:
1. Si un nodo desea solicitar un recurso, crea una solicitud con la hora actual, la agrega a su cola y la envía a todos los demás nodos.
2. Todos los demás nodos colocan esta solicitud en su cola y envían un mensaje de respuesta.
3. El nodo que libera el recurso envía un mensaje de liberación con la hora actual y elimina la solicitud original de su cola.
4. Cuando el nodo reciba el mensaje de liberación, borrará la solicitud relacionada de su propia cola.
5. Cuando un nodo tiene su propia solicitud en su cola antes que cualquier otra solicitud (en orden cronológico total), puede acceder libremente a ese recurso y recibe mensajes de todos los demás nodos después de ese tiempo.
El algoritmo anterior es un algoritmo descentralizado que cada nodo ejecuta de forma completamente independiente.Utiliza el reloj para clasificar las solicitudes de acuerdo con el orden general, para realizar el acceso a los recursos y la coordinación entre los nodos.
Bueno, aprendimos aproximadamente cómo usar estos relojes lógicos para ordenar eventos en un sistema distribuido a través del artículo y analizamos la aplicación práctica de determinar el orden cuando un sistema distribuido accede a los recursos. Los comentarios son bienvenidos y continuaré actualizando más artículos sobre sistemas distribuidos.
Título original: Tiempo, relojes y orden
Por Dean Eigenmann
compilar: pez estaca
Tags:
Después de oscilar durante tres días consecutivos, Bitcoin cayó bruscamente ayer y cayó por debajo de los $8,300, cayendo a $8,264 en un punto.Más temprano ese día, John Bollinger.
Los datos de Huobi Global anoche mostraron que XRP superó brevemente los $0,27, un nuevo máximo desde el 13 de noviembre del año pasado, con un aumento intradiario del 8,87%. Esta tarde.
A partir de la tendencia mensual histórica a largo plazo de 10 años de BTC, se puede ver que Bitcoin subió a la cúspide de cada ronda del mercado alcista en 2011, 2013 y 2017.
El "tiempo" es un tema eterno en los tiempos cambiantes. Se han producido debates sobre el tiempo en blockchains y otros sistemas distribuidos. El tiempo conecta procesos y nodos.
Jinse Finance informó el 3 de febrero que el grupo de expertos en políticas del gobierno indio, NITI Aayog, publicó un borrador de política nacional de blockchain llamado "Estrategia Blockchain-India".
Desde el 10 de enero de 2020, las empresas de activos digitales que operan en el Reino Unido deben cumplir con las regulaciones nacionales contra el lavado de dinero y el financiamiento del terrorismo (AML/CTF).La 5ª.
A juzgar por varios signos, el camino de desarrollo de la industria blockchain en el país y en el extranjero ha mostrado una diferenciación obvia, especialmente en comparación con Europa y los Estados Unidos.



